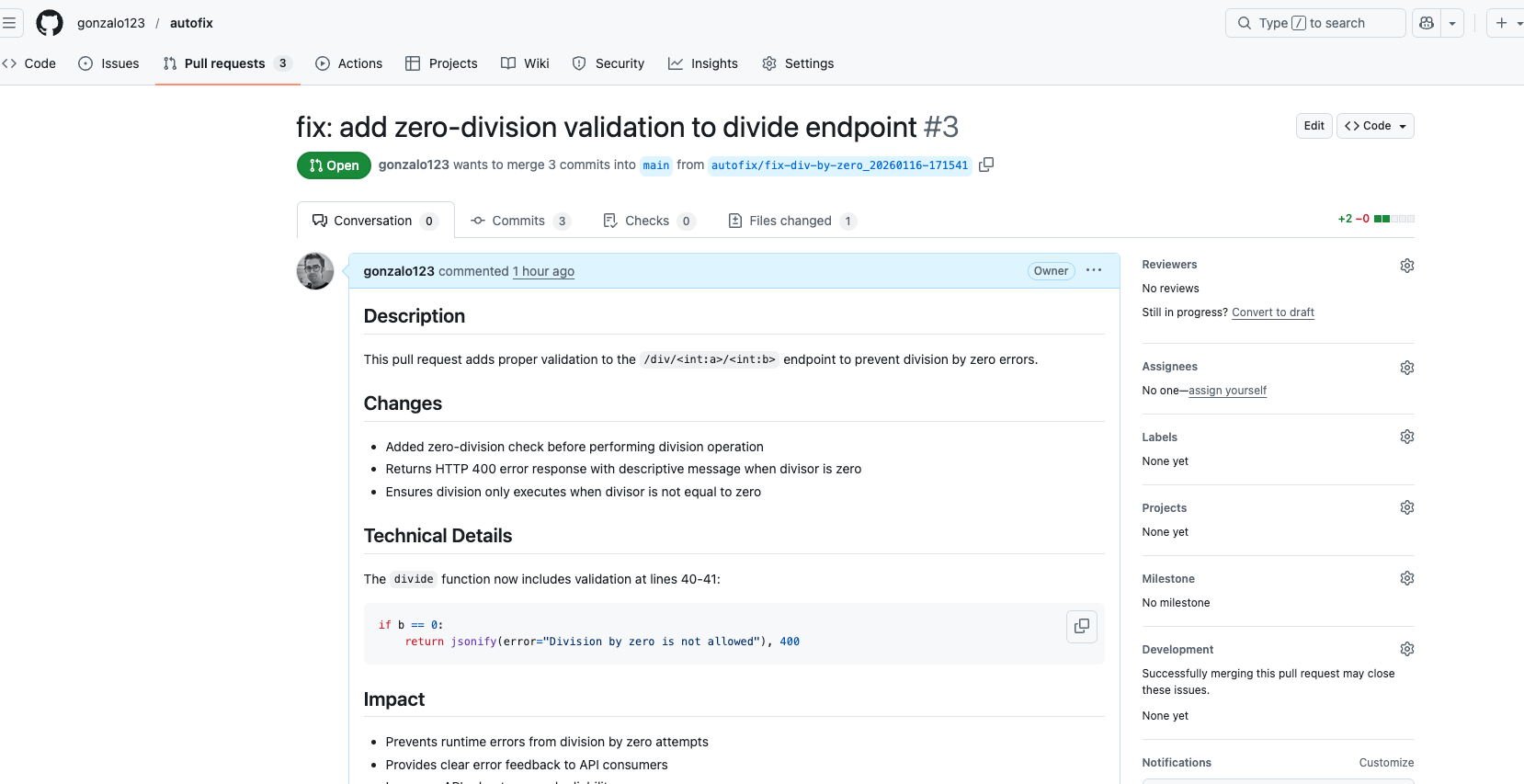
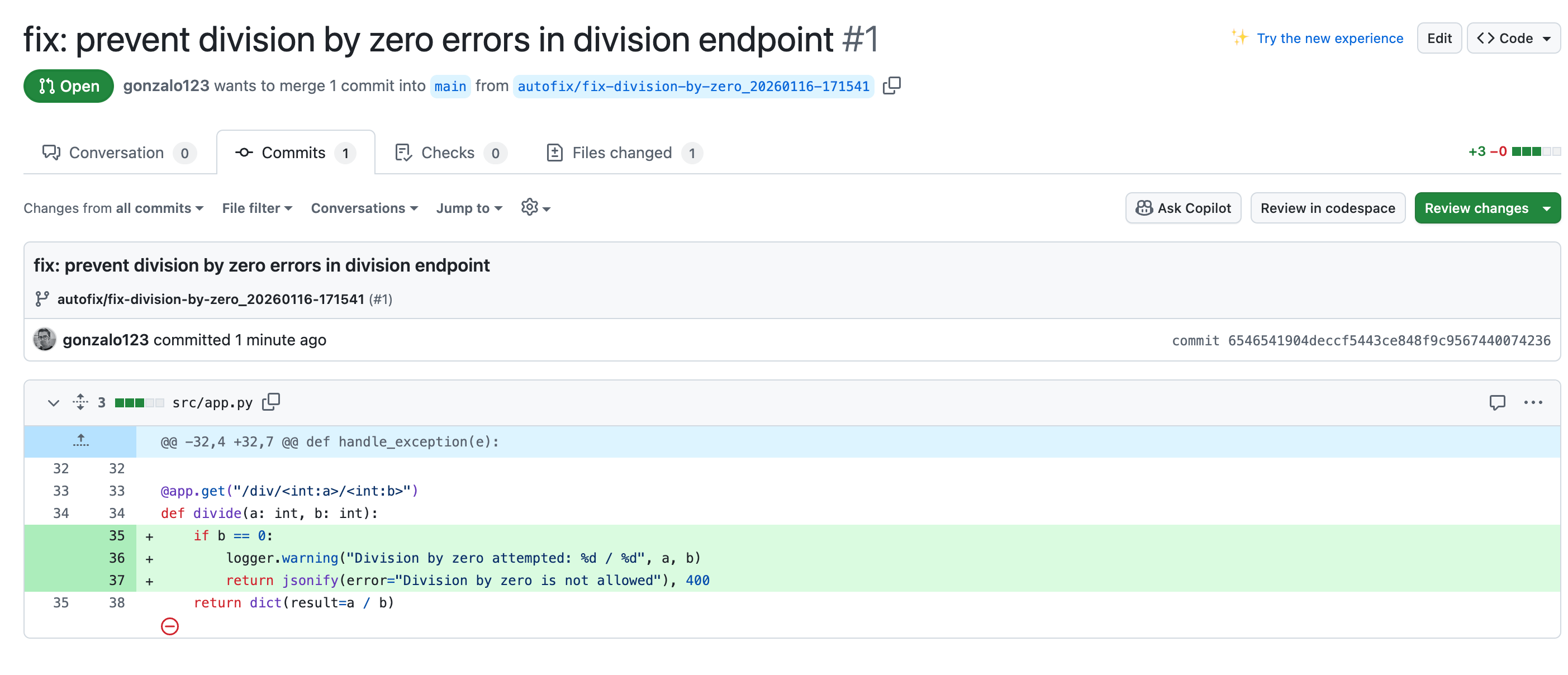
When you’re debugging production issues at 3 AM, the last thing you want is to scroll through thousands of CloudWatch log entries trying to find that one error. I’ve built a CLI tool that uses AWS Bedrock (Claude Sonnet 4.5) to analyze CloudWatch logs intelligently. You ask questions in natural language, and it gives you insights instead of raw log dumps.
This project is an exploration of combining AWS services with AI agents. Yes, it’s probably over-engineered for simple log queries, but it demonstrates interesting patterns for handling large datasets with parallel AI processing.
The Problem
CloudWatch Logs Insights is powerful, but it has limitations:
- You need to know the query syntax
- Results are raw data, not insights
- Large result sets are overwhelming
- Pattern recognition requires manual analysis
What if you could ask: “What errors occurred in the last 2 hours?” and get an intelligent summary instead of 10,000 raw log entries?
Architecture
The tool implements two interaction modes: direct CLI queries and an interactive agent.

Key Components
CloudWatch Insights Query Layer (modules/logs/main.py)
- Recursively subdivides time ranges when hitting AWS’s 10,000 result limit
- Parses natural language time ranges (“last 2 hours”, “since yesterday”)
- Supports custom CloudWatch Insights query syntax
Smart Dataset Routing
- Small datasets (2,000 logs): Parallel worker-coordinator pattern
- Configurable chunk size and max workers
Worker-Coordinator Pattern Each worker agent analyzes a chunk of logs (2,000 records), then a coordinator agent synthesizes all analyses into a coherent answer. This architecture allows processing 10,000+ log records efficiently while staying within Claude’s context limits.
Interactive Agent (agents/log_agent.py)
A specialized agent with access to the analyze_cloudwatch_logs tool, configured with known log groups and time parsing capabilities.
Technology Stack
- Python 3.13 with type hints and Pydantic models
- boto3 for AWS CloudWatch Logs API
- AWS Bedrock (Claude Sonnet 4.5) for AI analysis
- Strands Agents for agent orchestration and tool integration
- Click for CLI interface
Create your AWS credentials and configure the tool:
# Environment variables
AWS_REGION=eu-central-1
AWS_PROFILE_NAME=your-profile
MAX_CHUNKS_TO_PROCESS=5 # Safety limit for cost control
# Optional: Define known log groups
KNOWN_LOG_GROUPS="/aws/lambda/api,/aws/ecs/backend"
Configure known log groups in settings.py:
class LogGroups(StrEnum):
"""Known CloudWatch log groups for type-safe references."""
API_LAMBDA = "/aws/lambda/api"
BACKEND_ECS = "/aws/ecs/backend-service"
DATABASE_RDS = "/aws/rds/instance/prod/postgresql"
Now you can ask specific questions about your logs:
poetry run python src/cli.py log \
--group "/aws/lambda/api-handler" \
--question "What errors occurred?" \
--start "2025-12-20T10:00:00" \
--end "2025-12-20T12:00:00"
With custom CloudWatch Insights query:
poetry run python src/cli.py log \
--group "/aws/lambda/payment" \
--question "Analyze payment failures" \
--start "2025-12-20" \
--query "fields @timestamp, @message, userId | filter @message like /ERROR/"
Using natural language time ranges:
poetry run python src/cli.py log \
--group "/aws/ecs/backend" \
--question "What performance issues occurred?" \
--start "last 2 hours"
The project also allows us to launch an interactive session for exploratory analysis:
poetry run python src/cli.py agent
Example interaction:
============================================================
CloudWatch Logs Analysis Agent
============================================================
Ask me about your CloudWatch logs!
Examples:
- What errors occurred in /aws/lambda/api in the last hour?
- Analyze /aws/ecs/backend-service from last 2 hours for memory issues
- Show me exceptions in /aws/lambda/payment-api since yesterday
Type 'exit', 'quit', or 'q' to quit.
============================================================
> What errors happened in /aws/lambda/api in the last hour?
[Agent analyzes logs and provides intelligent summary]
> Were there any timeouts?
[Agent refines analysis based on context]
The agent mode maintains conversation context and can refine analyses based on follow-up questions.
CloudWatch Insights limits results to 10,000 records per query. The tool automatically subdivides time ranges when hitting this limit:
def query_chunk_recursively(log_group: str, start: datetime, end: datetime,
query: str, depth: int = 0) -> list[list[dict]]:
"""
Queries a time chunk and subdivides it recursively if it hits the result limit.
Returns all log entries for the given time range.
"""
status, rows = insights_query(log_group, start=start, end=end,
query=query, limit=MAX_RESULTS_PER_QUERY)
if len(rows) >= MAX_RESULTS_PER_QUERY:
# Subdivide in half
midpoint = start + (end - start) / 2
first_half = query_chunk_recursively(log_group, start, midpoint, query, depth + 1)
second_half = query_chunk_recursively(log_group, midpoint, end, query, depth + 1)
return first_half + second_half
return rows
This ensures you can analyze any time range without manual intervention, regardless of log volume.
For large datasets, logs are split into chunks and processed in parallel:
def analyze_chunk_with_worker(
chunk: LogChunk, question: str, log_group: str, global_metadata: dict
) -> ChunkAnalysisResult:
"""
Analyze a single chunk of logs using a worker agent.
Each worker gets chunk-specific context and the user's question.
"""
worker_prompt = WORKER_AGENT_PROMPT.format(
chunk_index=chunk.chunk_index + 1,
total_chunks=chunk.total_chunks,
chunk_size=chunk.chunk_size,
time_range=chunk.get_time_range_description(),
question=question,
)
worker_agent = create_agent(
system_prompt=worker_prompt,
model=Models.CLAUDE_45,
temperature=0.3,
read_timeout=WORKER_TIMEOUT_SECONDS,
)
chunk_context = {
"metadata": {...},
"logs": chunk.logs,
}
result = worker_agent(prompt=[
{"text": f"Question: {question}"},
{"text": f"Log context: {json.dumps(chunk_context)}"},
{"text": "Analyze this chunk of logs according to the guidelines in your system prompt."},
])
return ChunkAnalysisResult(...)
Workers run concurrently using ThreadPoolExecutor:
with ThreadPoolExecutor(max_workers=MAX_PARALLEL_WORKERS) as executor:
future_to_chunk = {
executor.submit(analyze_chunk_with_worker, chunk, question, log_group, global_metadata): chunk
for chunk in chunks
}
for future in as_completed(future_to_chunk):
result = future.result()
chunk_results.append(result)
After workers complete, a coordinator agent synthesizes their analyses:
def consolidate_with_coordinator(
chunk_results: list[ChunkAnalysisResult],
question: str,
log_group: str,
start: datetime,
end: datetime,
total_records: int,
) -> str:
"""
Use coordinator agent to synthesize chunk analyses into final answer.
"""
coordinator_context = {
"metadata": {
"log_group": log_group,
"time_range": f"{start.isoformat()} to {end.isoformat()}",
"total_records": total_records,
"total_chunks": len(chunk_results),
},
"chunk_analyses": [
{
"chunk_index": r.chunk_index + 1,
"time_range": r.chunk_time_range,
"analysis": r.analysis,
}
for r in successful_results
],
}
result = coordinator(prompt=[
{"text": f"Original Question: {question}"},
{"text": f"Chunk Analyses: {json.dumps(coordinator_context)}"},
{"text": "Synthesize these chunk analyses to answer the user's question."},
])
return str(result)
This pattern allows analyzing datasets far exceeding Claude’s context window while maintaining coherent insights.
The tool supports flexible time specifications:
# modules/logs/time_parser.py
def parse_time_range(time_range: str) -> tuple[datetime, datetime]:
"""
Parse natural language time ranges:
- "last 2 hours"
- "since yesterday"
- "2025-12-10 to 2025-12-12"
- "last 7 days"
"""
# Implementation handles various patterns
pass
The analyze_cloudwatch_logs tool integrates with Strands agents:
@tool
def analyze_cloudwatch_logs(
log_group: Annotated[Union[LogGroups, str], "CloudWatch log group name"],
question: Annotated[str, "Question to answer about the logs"],
time_range: Annotated[Optional[str], "Time range examples: 'last 2 hours', 'since yesterday'"] = None,
cloudwatch_sql: Annotated[Optional[str], "CloudWatch Insights query string"] = None,
) -> dict:
"""
Analyze AWS CloudWatch Logs to answer questions about application behavior.
Automatically handles large datasets through parallel chunking.
"""
# Parse time range
start_dt, end_dt = parse_time_range(time_range or "last 24 hours")
# Call the existing analysis function
analysis, metadata = ask_to_log(log_group, question, start_dt, end_dt,
cloudwatch_sql=cloudwatch_sql or DEFAULT_CW_SQL)
return {
"status": "success",
"content": [{"text": f"Analysis for log group '{log_group}':\n\n{analysis}"}],
"metadata": metadata,
}
This tool can be composed with other agent tools for more sophisticated workflows.
Each worker agent receives context about its role in the larger analysis:
WORKER_AGENT_PROMPT = """You are a CloudWatch Logs Analysis Worker Agent.
Role: Analyze a specific chunk of logs (part {chunk_index} of {total_chunks})
Time range: {time_range}
Chunk size: {chunk_size} log records
Your task:
1. Analyze this chunk for patterns, errors, anomalies related to: {question}
2. Provide factual observations, not speculation
3. Note timestamps for important events
4. Be concise - a coordinator will synthesize all chunks
Focus on:
- Error messages and stack traces
- Unusual patterns or spikes
- Performance indicators
- User-impacting events
Output format: Concise bullet points with timestamps.
"""
The coordinator synthesizes worker outputs into coherent insights:
COORDINATOR_AGENT_PROMPT = """You are a CloudWatch Logs Coordinator Agent.
Role: Synthesize analyses from {chunks_processed} worker agents
Dataset: {total_records} total log records
Time range: {time_range}
You've received chunk-level analyses. Your task:
1. Identify patterns across all chunks
2. Synthesize a coherent narrative answering the user's question
3. Highlight critical findings
4. Provide actionable insights
Output format:
- Executive summary
- Key findings (chronological if relevant)
- Patterns or trends observed
- Recommendations (if applicable)
Be direct and actionable. Focus on what matters.
"""
Processing large log volumes with AI can get expensive. The tool includes configurable safety limits:
# settings.py
MAX_CHUNKS_TO_PROCESS = int(os.getenv("MAX_CHUNKS_TO_PROCESS", "5"))
# In main.py
if len(chunks) > MAX_CHUNKS_TO_PROCESS:
error_msg = (
f"Dataset would generate {len(chunks)} chunks, which exceeds the maximum limit "
f"of {MAX_CHUNKS_TO_PROCESS} chunks.\n\n"
f"Options:\n"
f" 1. Reduce time range to analyze fewer logs\n"
f" 2. Increase MAX_CHUNKS_TO_PROCESS in settings\n"
f" 3. Use more specific CloudWatch Insights filters"
)
return f"ERROR: {error_msg}", {...}
With default settings (chunk size = 2,000, max chunks = 5), you can analyze up to 10,000 log records per query. Adjust these values based on your budget and requirements.
The project uses Pydantic for all data structures:
# modules/logs/models.py
class LogChunk(BaseModel):
"""Represents a chunk of logs for parallel processing."""
chunk_index: int
total_chunks: int
chunk_size: int
start_timestamp: str | None
end_timestamp: str | None
logs: list[dict[str, str]]
def get_time_range_description(self) -> str:
if self.start_timestamp and self.end_timestamp:
return f"{self.start_timestamp} to {self.end_timestamp}"
return "Unknown time range"
class ChunkAnalysisResult(BaseModel):
"""Result from a worker agent analyzing a chunk."""
chunk_index: int
chunk_time_range: str
chunk_size: int
analysis: str
success: bool = True
error_message: str | None = None
processing_time_seconds: float = 0.0
Let’s say you’re investigating a production incident:
# Step 1: Check what happened in the last hour
poetry run python src/cli.py log \
--group "/aws/lambda/payment-api" \
--question "What errors occurred?" \
--start "last 1 hour"
# Output:
# Analysis for log group '/aws/lambda/payment-api' from 2025-12-20T14:00:00 to 2025-12-20T15:00:00:
#
# Key Findings:
# - 47 payment timeout errors between 14:23 and 14:45
# - Errors clustered around Stripe API calls
# - No database connection issues observed
# - Timeout duration: consistently 30 seconds
#
# Pattern: All failures occurred during userId sessions starting with 'eu-'
# suggesting regional routing issue.
#
# [Metadata: 8,432 records, 5 chunks, 23.4s]
The agent identified the pattern (regional issue) and specific time window without you writing complex queries or manually reviewing logs.
This project is deliberately over-engineered. For simple log queries, CloudWatch Insights is sufficient. But building this taught me about:
- Managing AI context window limits at scale
- Worker-coordinator patterns for parallel processing
- Designing tools for agent consumption
- Balancing cost vs. capability in AI systems
We can use this tool effectively in scenarios like:
- Debugging complex incidents requiring pattern recognition
- Onboarding new team members who don’t know your query syntax
- Exploratory analysis where you don’t know what you’re looking for
- Generating incident reports from raw logs
When NOT to Use This:
- Real-time monitoring (use CloudWatch alarms)
- Known queries you run repeatedly (use saved Insights queries)
- Cost-sensitive environments (AI analysis adds expense)
AI agents transform log analysis from query construction to question asking. Instead of learning CloudWatch Insights syntax, you describe what you want to know. The worker-coordinator pattern demonstrates how to scale AI analysis beyond single-agent context limits.
Is it practical for every use case? No. Is it interesting to build and explore? Absolutely.
The complete implementation is available in my GitHub account.